70 Jahre, mehr als 4200 Sitzungen, 213 Millionen Wörter - seit der Gründung der Bundesrepublik Deutschland wird im Bundestag jede Rede, jeder Kommentar, jeder Zuruf protokolliert. Jedes einzelne Wort, das Abgeordnete im Plenarsaal sprechen, wird festgehalten. Eine gewaltige Menge von Texten, ein Datenschatz, der die jüngere Geschichte Deutschlands, einschneidende Entwicklungen, große politische Konflikte und Baustellen konserviert - all das, was die Republik bewegt.
Die Protokolle geben einen Einblick, wie der Bundestag über bestimmte Themen im Laufe der Zeit gesprochen hat, wie die Abgeordneten diskutiert haben, wie sich politische Debatten verändert haben. Sie können auch dabei helfen, Fragen zu klären, die in aktuellen gesellschaftlichen Debatten eine Rolle spielen, zum Beispiel ob die AfD die Grenzen des Sagbaren in Richtung Rechts verschoben hat oder ob die Klimakrise viel zu lange keine Rolle in der Politik spielte.
Eine Analyse auf Basis von Millionen Wörtern ist jedoch nur möglich mit Hilfe komplexer Algorithmen und automatisierter Rechenprozesse. Um die Bundestagsprotokolle von 1949 bis 2019 zu durchdringen, hat die SZ deshalb computerlinguistische Verfahren angewendet. Ein Algorithmus hat dabei Millionen von Wörter in Zahlen übersetzt und so etwa 455 Millionen Datenpunkte geliefert, die datenjournalistisch ausgewertet werden konnten.
Wie genau, das erklären wir hier: Fangen wir so an - oder vielmehr: Fangen Sie an. Mit diesem Tool können Sie einen Eindruck bekommen, worum es bei dieser Analyse geht. Wir haben mehrere Begriffe aus zwei großen Debatten zusammengestellt, die Deutschland derzeit beschäftigen und auch in der Vergangenheit immer wieder beschäftigt haben: Klima- und Migrationspolitik.
Das Tool verschafft Ihnen einen Einblick in die großen Konfliktlinien zweier zentraler Politikfelder der vergangenen 70 Jahre. Klicken Sie auf einen der Begriffe und Sie erhalten in einer Grafik eine Übersicht, in welcher Legislaturperiode die Abgeordneten wie über dieses Thema gesprochen haben. Entscheidend dabei: Das Tool zeigt die häufigsten Wörter, die in diesem Zusammenhang diskutiert wurden - es zeigt also den Kontext, den gesamten Rahmen der Debatte und deren Veränderungen über Jahre hinweg.
Solche Grafiken sind das Endergebnis eines langen Prozesses, in dem ein Algorithmus die Wörter in Zahlen übersetzt, ein Computer 30 Modelle durchrechnet - und am Ende Ergebnisse ausspuckt, die ein Mensch interpretieren kann. Wie genau der Algorithmus arbeitet und mehr über den wissenschaftlichen Hintergrund lesen Sie hier. Mit Hilfe dieser Ergebnisse haben wir versucht, uns den Daten aus 70 Jahren Bundestag anzunähern. Wir haben die Grafiken und Wörterlisten interpretiert, haben Einschätzungen diskutiert und mit Experten besprochen.
Zum Beispiel wird deutlich, dass die Abgeordneten noch nie so heftig wie heute über Klimapolitik gestritten haben, auch wenn das Thema bereits seit den Achtzigerjahren immer wieder debattiert wurde. Damit lässt sich ein Stück weit erklären, warum das Thema Klimawandel mitunter stiefmütterlich behandelt wurde. Auch welche Rolle Klimaleugner wann und wie gespielt haben, können Sie hier nachlesen:

Über Flucht und Migration ist noch nie so intensiv debattiert worden wie in jüngster Zeit. An den Daten aus den Bundestagsprotokollen lässt sich ablesen, dass die Art und Weise, wie die Politik über das Thema spricht, sich zuletzt stark verändert hat: Der Diskurs ist nach rechts gerückt - auch durch den Einfluss der AfD. Woraus sich das ableiten lässt und wie weit diese Tendenz geht, erfahren Sie hier:

Der Kontext macht die Bedeutung
Für Auswertungen wie diese müssen zwei Bereiche zusammenkommen: Sprachwissenschaft und Informatik. Maschinelle Sprachverarbeitung oder Computerlinguistik heißt das Forschungsgebiet. Im Grunde kommen wir alle ständig damit in Berührung, zum Beispiel bei einer einfachen Google-Suche, oder wenn Texte von einer Sprache automatisch in eine andere übersetzt werden. Die computerlinguistischen Verfahren, die dem zu Grunde liegen, können auch dabei helfen, Diskurse im Bundestag zu analysieren.
Natürlich versteht ein Computer Sprache nicht auf dieselbe Weise, wie Menschen das tun. Stattdessen erschließen mathematische Systeme, mit denen die Computerlinguistik arbeitet, die Bedeutung eines Wortes aus seinem Kontext. Je nachdem, mit welchen anderen Wörtern eine Vokabel verwendet wird, ändert sich die Interpretation.
Zum Beispiel das Wort „Läufer“: Es kann etliche verschiedene Bedeutungen haben - vom Teppich zur Schachfigur. Was „Läufer“ in einer bestimmten Situation heißt, wird nur aus dem Kontext klar: Ist die Szenerie ein Flur oder ein Schachbrett? Geht es um Innenausstattung oder um Spieltaktik? Und wie soll ein Computer das auseinanderhalten können?
Auch in den Bundestagsprotokollen finden sich solche Begriffe, deren Bedeutung nicht eindeutig ist oder die sich im Laufe der Zeit gewandelt hat. Das zeigt sich zum Beispiel am Wort „Umwelt“. Viele Male ist es seit 1949 im Parlament verwendet worden, doch die reine Häufigkeit sagt nichts darüber aus, wie das Wort eingesetzt wurde: Seit dem Einzug der Grünen 1983 in den Bundestag wird „Umwelt“ im Zusammenhang mit Naturschutz oder Artenvielfalt verstanden. Aber noch in den Fünfziger- und Sechzigerjahren wurde „Umwelt“ ganz anders verwendet: im Sinne der uns umgebenden Welt.
Wohnungspolitik, Resozialisierung von Straftätern, Agrarwirtschaft: Drei unterschiedliche Themenbereiche, bei denen Rednerinnen und Redner sich des Wortes „Umwelt“ bedienten. Das zeigt: Es reicht längst nicht aus, lediglich zu zählen, wie häufig ein Wort vorkommt, um politische Debatten des Bundestags nachzuzeichnen. Dann ginge die Information verloren, in welchem Zusammenhang ein Wort verwendet wurde.
„Du sollst ein Wort an seiner Gesellschaft erkennen“, sagte der Linguist John Rupert Firth 1957, lange bevor Computer dazu genutzt wurden, inhaltliche Kontexte zu finden. Und trotzdem gilt das Prinzip auch im 21. Jahrhundert noch, wenn Algorithmen diese Aufgabe übernehmen können.
Wenn Wörter zu Zahlen werden
Ein Computer ist eine recht eingeschränkte Maschine. Ein darin ablaufender Algorithmus ist ein mathematisches Regelwerk und kann nur Informationen einer bestimmten Form verdauen: Zahlen. Und trotzdem sind diese Rechenprozesse in gewisser Hinsicht dem menschlichen Denken überlegen. Denn Computer können Zahlen sehr viel effizienter verarbeiten als Gehirne.
Das Problem in unserem Fall: Bundestagsreden bestehen nicht aus Zahlen, sondern aus Sätzen. Damit sich Menschen der Überlegenheit von Computern bedienen können, müssen die gesprochenen Worte zu Zahlen werden. Diese Übersetzung übernimmt ein Algorithmus und liefert eine Art Vokabelheft: links das Wort auf Deutsch, rechts eine lange Liste aus Zahlen.
In der Fachsprache heißt dieses Vokabelheft Modell, ein vom Computer konstruiertes Abbild der Sprache, jeweils abhängig vom Ausgangsmaterial, in unserem Fall also den Bundestagsprotokollen.
Ein solches Modell sieht auf den ersten Blick unspektakulär aus: Im Fall der aktuellen Legislaturperiode ist es im Grunde eine große Textdatei mit mehr als 61 000 unterschiedlichen Wörtern, eines in jeder Zeile. Die Wörter aus den Redeprotokollen stehen auf der linken Seite des Vokabelheftes. Die rechte Seite nimmt in der Breite deutlich mehr Platz ein: 300 Zahlen, allesamt Werte zwischen -1 und 1, pro Zeile. Jede Zeile, also ein Begriff zusammen mit seiner Übersetzung in Zahlen, beschreibt den Kontext eines Wortes, den es braucht, um maschinell Bedeutung aus Texten ziehen zu können. In der Fachsprache heißt so eine Wort-Zahlen-Kombination Vektor.
So lange Zahlenkolonnen braucht es, weil Sprache, ihre Bedeutungen und Zusammenhänge komplex sind. Die Zahlen sollen möglichst viele Details abbilden. Und je länger die Zahlenreihe, desto mehr Details können darin widergespiegelt werden - theoretisch. Praktisch ist die Anzahl allerdings abhängig von der Textmenge. Je mehr Futter der Algorithmus bekommt, desto mehr kann er trainieren, desto besser wird das Modell - und damit das Ergebnis. Das heißt, die Zahlen in der Tabelle werden umso exakter und aussagekräftiger, je mehr Wörter der Algorithmus in seinem Training verarbeitet hat. Wenn ein Wort zu selten vorkommt, sind die Ergebnisse, die Zahlen im Wortvektor, nicht belastbar.
Während des Trainings hat der Algorithmus nicht nur gelernt, welche Wörter nebeneinander stehen. Er lernt über das massenhafte Betrachten von Wortpaaren auch die Struktur unserer Sprache kennen und kodiert sie in den Spalten des Modells. Zum Verständnis kann ein fiktives Beispiel beitragen: die vier Vektoren „Bundeskanzlerin“, „Frau“, „Mann“ und "Bundeskanzler“. Zur Anschaulichkeit verkürzen wir die Vektoren auf vier Dimensionen, die Zahlen sind erfunden.
Der Computer hätte in diesem Beispiel etwa die Kategorie „Weiblichkeit“ gelernt, zu sehen in der ersten Spalte. Die Vektoren Bundeskanzlerin und Frau haben dort hohe Werte. In der Spalte „Männlichkeit“ sind die Werte entsprechend niedriger, dafür bei Mann und Bundeskanzler sehr hoch.
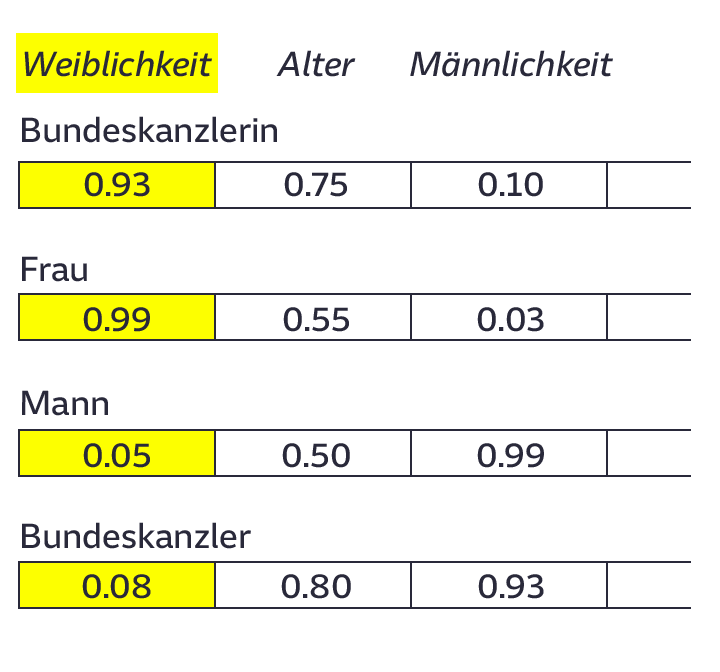
Wenn Wörter zu Zahlen werden, heißt das: Man kann mit ihnen rechnen. Das widerspricht all unseren Erfahrungswerten, spontan fremdeln Menschen mit der Vorstellung. Aber mit Blick auf die obige Tabelle ist es eigentlich ganz einfach: Die Zahlen aus den 300 Spalten eines Wortes werden mit den Zahlen aus den Spalten eines anderen Wortes verrechnet. Weil die Wörter einen gewissen Bezug zueinander haben, sind sinnvolle Kalkulationen möglich.
Wer also vom Vektor des Wortes Bundeskanzlerin die weibliche Komponente abzieht und dafür die männliche addiert, erhält das männliche Äquivalent: Bundeskanzler. Das, was auf einer rein mathematischen Ebene passiert, entspricht dann im Ergebnis exakt unserer Welterfahrung, wir können es auch semantisch nachvollziehen.
Wenn Zahlen zu Geschichten werden
Oben haben wir beschrieben, wie sich Wörter in Zahlen verwandeln lassen. Das haben wir auch mit den mehr als 4200 Protokollen des Bundestags gemacht. Alle Reden aller Abgeordneten hat ein Computer in Zahlen übersetzt. Damit ist die menschliche Sprache für den Computer lesbar oder berechenbar geworden, das heißt wir können nun diese immense Datenmenge mit seiner Hilfe durchsuchen, analysieren, verarbeiten. Aber wie können wir sie verstehen?
Der Schlüssel dafür ist der Kontext eines Wortes: Er ergibt sich daraus, welche anderen Begriffe in seiner Nähe vorkommen. Zum Beispiel fragt man die Vokabelhefte des Bundestags danach, welche Wörter ähnlich wie „Umwelt“ verwendet wurden. Solche Vokabelhefte lassen sich für jede einzelne der 19 Legislaturperioden erstellen und für jede einzelne Legislaturperiode spuckt der Computer eine entsprechende Antwort aus. Durch die einem Wort ähnlichsten Begriffe werden im Zeitverlauf auch Vergleiche und die Einsicht in die Bedeutungsänderungen möglich.
Wenn wir nun den Computer fragen, welche Wortvektoren aus den Bundestagsprotokollen unserem Beispiel von oben, Umwelt, am nächsten sind, bekommen wir pro Legislaturperiode folgende Wörter:
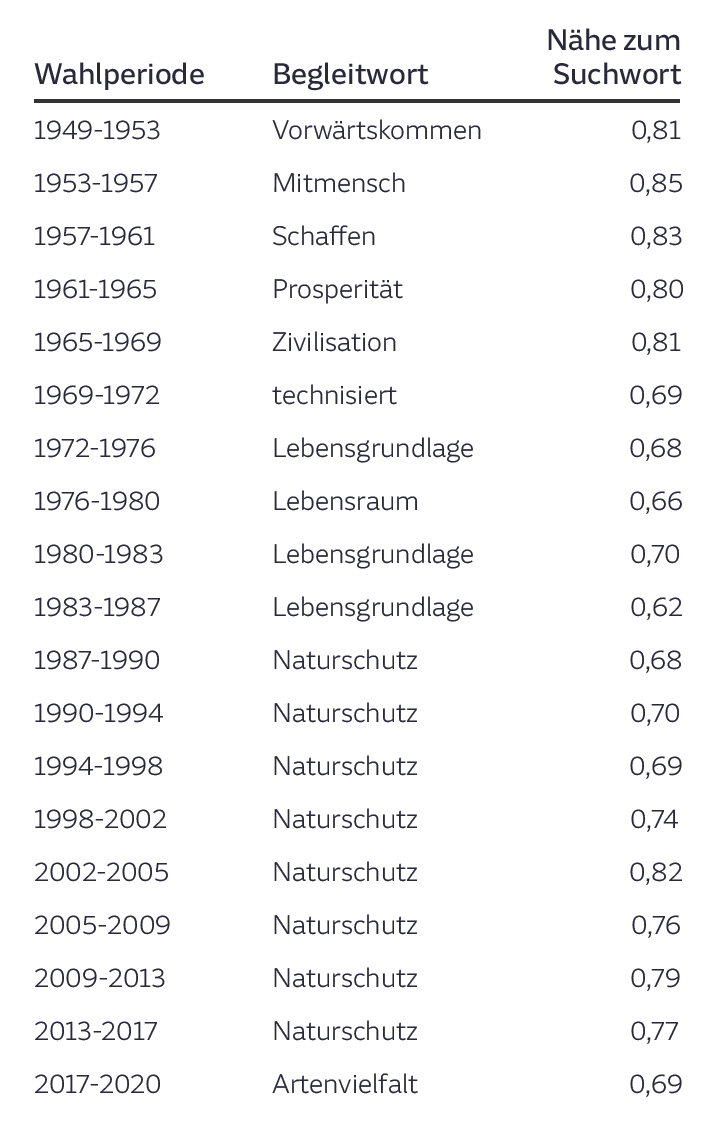
In der linken Spalte stehen die Legislaturperioden, in der Mitte die Wörter, die Umwelt in eben dieser Legislaturperiode am ähnlichsten sind, und ganz rechts wird in Werten von 0 bis 1 angegeben, wie ähnlich der Begriff dem Wort „Umwelt“ ist - je höher, desto ähnlicher.
„Lebensraum“, „Naturschutz“, „Artenvielfalt“ - das sind alles Begriffe, die auch ein Mensch im Zusammenhang mit „Umwelt“ vielleicht erwarten würde, die Ähnlichkeit ist also auch semantisch und nicht nur mathematisch nachvollziehbar.
Diese Wörterliste hat aber einen Haken: Auch wenn der Computer sich strikt an mathematische Regeln hält, ist es nicht garantiert, dass die Liste beim zweiten, dritten oder 27. Versuch wieder genauso aussieht. Das liegt an der Eigenständigkeit des Algorithmus und an den dahinter liegenden Regeln des neuronalen Netzes. Stößt man den Rechenprozess immer wieder neu an - mit denselben Daten, dem identischen Programmiercode und den exakt gleichen Einstellungen beim Algorithmus -, fallen die Ergebnisse jedes Mal ein wenig anders aus.
Diese Varianz stellt Wissenschaftler immer wieder vor Herausforderungen. Computerlinguisten haben diese Unschärfen untersucht und eine Lösung (PDF in Englisch) gefunden: Wenn man viele Varianten berechnet, kann man sich auf die Ergebnisse stützen, die wiederkehrend vorkommen. Es ist ein bisschen wie bei Zeugenbefragungen: Je mehr Leute man befragt, was sie gesehen haben, desto eher bekommt man einen verlässlichen, also dem eigentlichen Geschehen näheren Bericht.
Wir haben deshalb pro Legislaturperiode nicht nur ein Modell, sondern gleich 30 für jede einzelne der insgesamt 19 Legislaturperioden berechnen lassen. Und unsere Thesen und Aussagen über die Diskurse des Bundestags beziehen sich nur auf solche Fälle, bei denen ein Wort in möglichst vielen der 30 Modelle pro Legislaturperiode immer als ähnliches Wort gewertet wird. Das heißt: Wenn ein Wort sehr häufig oder sogar immer vorkommt, dann ist es mehr als wahrscheinlich, dass es dem untersuchten Wort mathematisch und damit auch im sprachlichen Kontext sehr nahe ist.
Um auch wirklich sicher zu stellen, dass die Analyse valide und der Befund reproduzierbar ist, haben wir die Modelle einmal komplett gelöscht und neu berechnet. Die Ergebnisse fallen wieder genau so aus wie zuvor.
Wenn man den Computer nun also für jede Legislaturperiode 30 Mal die ähnlichsten Wörter für Umwelt berechnen lässt, kommt ein Ergebnis heraus, das sich in der Grafik unten darstellen lässt. Sie zeigt, welche Wörter über alle Legislaturperioden hinweg am häufigsten und verlässlichsten dem Wort „Umwelt“ besonders ähnlich sind. Die blaue Färbung zeigt, in wie vielen Modellen einer Legislaturperiode das Wort stabil vorkommt: je dunkler, desto verlässlicher. Hier werden auch diejenigen Worte gezeigt, die weniger als 30 Mal pro Legislaturperiode vorkommen. Dadurch werden Entwicklungen sichtbar, also wenn zum Beispiel ein eher schwaches, weniger nahes Wort über mehrere Legislaturperioden immer dunkler und damit ähnlicher und im Bedeutungsraum wichtiger wird, ist das farblich nachvollziehbar.
Die dunkelste Farbe bekommen nur Worte die tatsächlich in allen Modellen vorkommen. Dann nimmt die Intensität schnell ab. In die zweite Kategorie fallen Worte mit Häufikeiten von 20 – 29, die beiden unteren drittel bekommen jeweils eine hellere Farbe. Weiß bedeutet, dass ein Wort in diesem Zeitraum gar nicht genannt wurde.
Auffällig ist auch: Auf der linken Seite, also in den früheren Legislaturperioden, sind weniger Farbpunkte, mehr Lücken. Denn bis in die Sechziger- und Siebzigerjahre hinein gibt es wenig Daten, weil das Wort Umwelt eher selten benutzt wird. Das ändert sich durch den Einzug der Grünen in den Bundestag und den Bedeutungswechsel des Begriffs. Heute gibt es mit der Umweltpolitik ein ganzes Politikfeld, das sich dem Thema widmet.
Alle Beiträge des Projekts #sprachemachtpolitik
Fast 40 Jahre lang hat Norbert Lammert das Innenleben des Bundestag studiert, als Abgeordneter und als Präsident. In diesem Interview blickt er auf einschneidende Momente zurück, erklärt, wie sich Debatten verändert haben und wie mit Provokationen umzugehen ist.

Diesmal haben wir den Bundestag mit Hilfe von Algorithmen, Wordvektoren und Modellen betrachtet. Vor knapp zwei Jahren hat die SZ schon einmal eine datenjournalistische Untersuchung der Bundestagsprotokolle veröffentlicht. Damals haben wir die Metadaten der parlamentarischen Debatten analysiert, um herauszufinden, welche Fraktion zum Beispiel für welche Fraktion klatscht und wer über wen lacht. Damals war der 19. Bundestag erst ein halbes Jahr alt und die AfD noch neu. Jetzt, nach der Halbzeit dieser Legislaturperiode, haben wir diese Untersuchung fortgesetzt und überprüft, was sich seitdem verändert hat:

Aber von Daten und Protokollen einmal abgesehen - wie tickt eigentlich der Bundestag? Wie funktioniert er, wie hat er sich entwickelt, was waren die großen Themen, Debatten und Momente der vergangenen 70 Jahre? In diesen Beiträgen aus dem großen SZ-Schwerpunkt #sprachemachtpolitik können Sie hinter die Kulissen des Parlaments schauen:


